Frequently we are interested in more than one treatment factor in an experiment. There are many things we can control or change—which have a causal effect on the response, and which combination yields the best response?
For example, suppose we are growing corn. We have easy control over many treatment factors:
The amount of manure to spread on the field
The amount of chemical fertilizer to spread on the field
The variety of corn to plant
The amount of pesticides to spray on the field
The amount of water to provide through irrigation
The type of soothing music to play to the corn as it grows
And so on and so on. The response is yield, i.e. the amount of corn produced per unit land area. Ultimately we believe there is some function \[
\text{yield} = f(\text{manure}, \text{fertilizer}, \text{variety}, \dots, \text{???}),
\] where the dots indicate other known variables and “???” indicates the many unknown or unmeasurable factors that also affect yield. And the function \(f\) can be arbitrarily complicated. How do we sort out the effects of each variable?
One option: Fix all but one variable and change the others. This is sometimes quoted as a rule of science—we must change only one thing at a time, so we can be certain it is that thing that caused the change. So we pick one fertilizer amount, one corn variety, and so on, and try planting with three different amounts of fertilizer. Once we understand the effect of fertilizer, we fix it at a particular value and try different corn varieties. Then we fix that and try different pesticide amounts. And on and on.
This is called the “one-factor-at-a-time”, or OFAT, approach. It doesn’t work (Czitrom 1999). There are several problems:
What if the effect of manure depends on the type of corn? Some likes more, some likes less. (TODO draw an interaction plot showing the swap) In an OFAT experiment, we’d never know.
OFAT experiments covering all the factors would require many experiments each with several units (several fields tested). We can obtain the same information with many fewer total units by designing a single experiment for all factors.
We can find the optimal combination of treatments much faster with one experiment than with OFAT, which can be seen as a kind of bad iterative optimizer.
TODO draw the two-D design space for the fertilizer experiment, comment on interactions
Based on the diagram, we can start seeing the fundamental randomized design in multi-factor experiments: the completely randomized factorial design.
7.1 Factorial designs
An experiment with more than one treatment factor is often called a factorial experiment. Factorial experiments can have any number of factors, each with any number of levels, so there’s a convenient notation to use to describe them.
Definition 7.1 (Factorial experiment notation) A factorial experiment with \(k\) factors, each in \(l\) levels, is called an \(l^k\) experiment. For example, an experiment with three binary treatment factors is a \(2^3\) experiment.
If some factors have different numbers of levels, we write a product: a \(2^4
3^2\) experiment has 4 binary treatment factors and two factors with three levels.
If we evaluate the notation numerically, we get the number of total treatment combinations: a \(2^4 3^2\) experiment has \(16 \times 9 = 144\) total possible treatment combinations.
Factorial experiments are typically crossed, meaning we can observe all combinations of all treatment factors. Factorials where we do not observe all combinations pose special problems we might consider later.
Let’s begin by considering factorial designs with two factors and without blocking, for simplicity.
The first question to ask is: What’s the difference between having two factors, each in several levels, and having one factor and one blocking variable?
There is, of course, the conceptual difference that blocking variables are usually nuisance variables, and we only care about their effects insofar as they reduce the variance of our estimates of the treatment effects. And there is the crucial difference that we can assign treatment, but we cannot always assign the value of a blocking variable.
But consider the analysis stage, not the design and implementation of the experiment. Orthogonal blocks are desirable because having equal numbers of each treatment in each block ensures that the block effects are equally included in all treatments, and hence do not alter estimates of the difference between treatments. Or, to restate in another way, orthogonal blocks eliminate the covariance between block effect and treatment effect estimates. The same logic applies to treatments. Orthogonal treatments will make the same treatment main effects orthogonal to each other.
It follows that we want to design the experiment—design the treatment assignment process—to control the number of units in each treatment combination. This leads to a factorial version of a completely randomized experiment (Definition 4.4).
Definition 7.2 (Completely randomized factorial experiments) In an experiment with \(k\) treatment factors, each with a fixed number of levels, a completely randomized experiment fixes the number of units to receive each unique treatment combination. For each treatment combination, these units are drawn uniformly at random, and without replacement, from the \(n\) units in the population.
If the number of units receiving each treatment combination is equal, this is a balanced experiment.
7.2 Linear models for factorials
Again, consider a factorial design with two factors and without blocking. We can choose a basic linear model: \[
Y_{ijt} = \mu + \tau_{ij} + \epsilon_{ijt},
\] where \(i \in \{1, \dots, v_1\}\) is the level of treatment 1, \(j \in \{1, \dots,
v_2\}\) is the level of treatment 2, \(t \in \{1, \dots, r_{ij}\}\) is the experimental unit, and \(r_{ij}\) is the number of replicates in treatment combination \(ij\). The errors \(\epsilon_{ijt}\) are assumed to be mean 0 and uncorrelated. As before, the model implies that \[
\E[Y_{ijt}] = \mu + \tau_{ij}.
\] All the same considerations of Section 6.3 apply here: The parameters are not identifiable as written, but treatment means are estimable.
With this two-way model, we can write two-way contrasts: contrast vectors are now indexed \(c_{ij}\), and are estimated by summing over both treatments. But what contrasts do we want?
Consider a sample \(2^2\) experiment with corn, where the two treatments are corn type and fertilizer amount. Treatment means are shown in Table 7.1.
Table 7.1: Yields for different treatment combinations in a corn experiment, presented as treatment means \(\bar Y_{ij}\).
Corn type
Low fertilizer
High fertilizer
Basic corn
10
12
MegaCorn Pro 3.5
14
18
We can summarize this data in three ways:
We can consider the difference between high and low fertilizer use, both for basic corn and MegaCorn Pro 3.5. For basic corn, increasing the fertilizer use seems to raise yield by 2; for MegaCorn, it increases the yield by 4. Also, MegaCorn starts with 4 higher yield than basic corn.
We can consider the difference between basic corn and MegaCorn, both for low and high fertilizer. With low fertilizer use, MegaCorn has 4 higher yield; for high fertilizer use, it has 6 higher yield. Also, high fertilizer starts out with 2 higher yield than low fertilizer.
On average, high fertilizer has 4 higher yield than low fertilizer (\(16 - 12
= 4\)). And on average, MegaCorn has 5 higher yield than basic corn (\(16 - 11
= 5\)). But the fertilizer effect is larger for MegaCorn than it is for basic corn; or, to say it another way, the MegaCorn effect is higher for high fertilizer than for low fertilizer.
All of these ways are equivalent: they describe the same table of mean responses. But they may be better or worse for specific problems. If I care mainly about the effect of fertilizer, so I know the best fertilizer to use in a situation, option 1 seems best; if I care mainly about corn variety, I might use option 2. But option 3 seems to cover both bases, and it is what is commonly done.
7.2.1 Breaking effects into pieces
To implement this, we break the factorial model into pieces: \[\begin{align*}
Y_{ijt} &= \mu + \tau_{ij} + \epsilon_{ijt}\\
&= \mu + \underbrace{\alpha_i + \beta_j}_\text{main effects} +
\underbrace{(\alpha \beta)_{ij}}_\text{interaction} + \epsilon_{ijt}
\end{align*}\] Here \(\alpha\) gives main effects for the first treatment, \(\beta\) gives main effects for the second treatment, and \((\alpha \beta)\) is not the product of those two; it is a separate parameter or set of parameters, indexed by \(i\) and \(j\).
If it helps, think of the equivalent \(Y = X\beta + \epsilon\) form of this model for the case where the two treatments are binary: \[
Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_1 X_2 + \epsilon.
\] This is the familiar interaction model from linear regression. If \(X_1\) and \(X_2\) are binary, this model predicts four means, one for each treatment combination. The means are the same ones shown in Example 6.3, so there is a correspondence in the estimable parameters, as shown in Table 7.2.
Table 7.2: Comparison of cell means as defined in the two different ways to write a linear model for a factorial experiment.
(a) Cell means as defined in the \(Y = X\beta + \epsilon\) model.
\(Z_i = 0\)
\(Z_i = 1\)
\(X_i = 0\)
\(\beta_0\)
\(\beta_0 + \beta_1\)
\(X_i = 1\)
\(\beta_0 + \beta_2\)
\(\beta_0 + \beta_1 + \beta_2 + \beta_3\)
(b) Cell means as defined in the \(Y_{ijt} = \mu + \alpha_i + \beta_j +
(\alpha\beta)_{ij} + \epsilon_{ijt}\) model.
By breaking the effects into pieces, we can impose additional structural assumptions. For example, the most common one is the assumption that \((\alpha
\beta)_{ij} = 0\) for all \(i\) and \(j\): in other words, there is no interaction.
In essence, we are rewriting \[\begin{align*}
Y_{ijt} &= \mu + \tau_{ij} + \epsilon_{ijt}\\
&= \mu + \alpha_i + \beta_j + \epsilon_{ijt},
\end{align*}\] so \(\tau_{ij} = \alpha_i + \beta_j\). This imposes structure on the treatment means. For example, if we have one factor with two levels and one with three, we might have \[
\begin{pmatrix}
\tau_{11} & \tau_{12} \\
\tau_{21} & \tau_{22} \\
\tau_{31} & \tau_{32}
\end{pmatrix} =
\begin{pmatrix}
\alpha_1 & \alpha_1 \\
\alpha_2 & \alpha_2 \\
\alpha_3 & \alpha_3
\end{pmatrix} +
\begin{pmatrix}
\beta_1 & \beta_2 \\
\beta_1 & \beta_2 \\
\beta_1 & \beta_2
\end{pmatrix}.
\] Notice that, for any \(i\), \(\tau_{i2} - \tau_{i1} = \beta_2 - \beta_1\), and for any \(j\), \(\tau_{2j} - \tau_{1j} = \alpha_2 - \alpha_1\). By eliminating the interaction, we have made the effects additive. Changing the level of treatment factor \(\alpha\) has the same effect regardless of treatment factor \(\beta\), and vice versa.
7.2.2 Deciding whether to include interactions
How can we justify the assumption that \((\alpha \beta)_{ij} = 0\)? It is a very specific assumption about the structure of the factors and the response. First, let’s understand its implications.
Back in the causal version of experimental design, we never assumed a particular model structure—meaning, essentially, we always allowed interactions. Consider how we defined the block average treatment effect, for instance (Definition 5.2): we calculated the treatment effect separately for each block, as though they could all be different, and then averaged them together.
In a linear model, omitting an interaction does essentially the same thing: The main effect coefficient is the average effect for that treatment factor, even if the effect varies depending on the level of a different treatment or blocking factor.
Whether that’s acceptable depends upon your goal. If you want a population average treatment effect, you’re averaging over a blocking factor, and the blocking factor levels appear in your experiment in the same proportions they appear in the population, that may be fine. Your average treatment effect will estimate the population average.
But if you have multiple treatment factors in proportions you chose, and you’d like to know how their affects by level of other factors, you may need to account for interactions. Before you analyze your data, you should consider whether an interaction may be present and select your model accordingly. How can you do this?
A starting point is some basic EDA. Interaction plots can make the presence of interactions visually apparent.
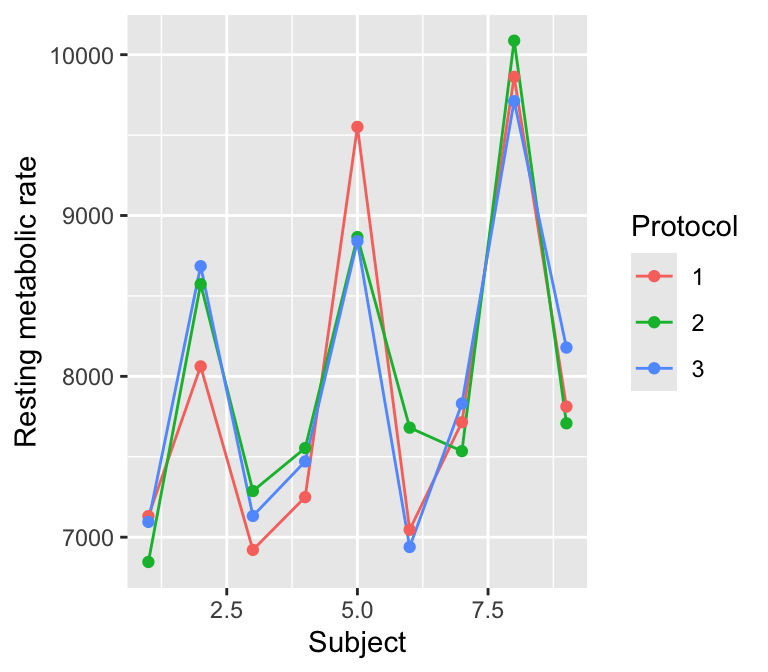
Example 7.1 (Resting metabolic rate interaction) Let’s return to the resting metabolic rate data from Example 6.4. How can we visualize subject, protocol, and the measured resting metabolic rate in one plot?
There are many options, of course. But we’d specifically like one that can tell us if the relationship between protocol and metabolic rate varies by subject. This suggests a pattern that is often called the interaction plot. We can easily construct one:
library(ggplot2)rmr <-read.table("data/resting.metabolic.rate.txt",header =TRUE)ggplot(rmr, aes(x = subject, y = rate, color =factor(protocol))) +geom_line() +geom_point() +labs(x ="Subject", y ="Resting metabolic rate",color ="Protocol")
A conventional visualization course would tell you that this is a bad plot. By connecting the dots, we are implying that there is some kind of trend from subject to subject—but the order of subjects is completely arbitrary, and they could be numbered or labeled in any way we want.
But to detect an interaction, we want to see the gap between the lines. In a purely additive model, each line would be shifted above or below the other by a constant amount. Human visual perception is very good at telling if lines are parallel, and if they are not, we know there is an interaction.
Here the differences are not particularly large, except maybe protocol 2 for subject 6. If there is an interaction, the effects are small enough that they’re not relevant—we see nothing here that passes the intraocular trauma test.
Beyond visualization, we can use statistical inference, though it’s usually best to select the model before you begin analyzing data rather than after.
7.3 Inference
Estimation is done with ordinary least squares: think of each treatment factor as a covariate in linear regression, and fit the model using standard regression techniques. One can derive specific formulas for estimates, but this is not necessary when analyzing data using computers.
7.3.1 Analysis of variance
However, while it is no longer necessary to calculate ANOVA tables by hand to do inference, constructing an ANOVA table can help us understand the benefits of factorial designs and how to construct them.
Consider an experiment with two treatment factors, \(r_{ij}\) units in level \(i\) of treatment A and level \(j\) of treatment B, \(n\) total units, and orthogonal treatment allocation. Suppose we fit main effects without the interaction. Because of orthogonality, the total variance decomposes just as it does in orthogonal block designs (Theorem 6.8), leading to the decomposition \[
\text{SST} = \text{SSR}_A + \text{SSR}_B + \RSS,
\] where the terms are defined as in Table 7.3.
Table 7.3: An ANOVA table for an orthogonal two-factor factorial design.
Example 7.2 (A \(2^2\) factorial) Consider a \(2^2\) factorial where \(r_{ij} = 1\), so there is only one unit per treatment combination. Then \(n = 4\) and the degrees of freedom are
Variation
DF
Treatment A
1
Treatment B
1
Error
1
Total
3
There is at least one DF available for each term, so they can be estimated; if we chose a model where the error DF is 0, the fit would be perfect with \(\RSS =
0\), and \(\sigma^2\) could not be estimated.
Increasing the number of replicates does not change the treatment DFs, which depend only on the number of levels for each factor. (It does, however, improve the power of the experiment to detect differences between treatments, as we will see in Chapter 8.) Instead it increases the error DF, essentially meaning more observations are available to estimate \(\sigma^2\). To a point this is beneficial, as when \(\hat \sigma^2\) has high variance we are just as liable to get a high estimate (and hence wide confidence intervals) as a low one. But having 100 degrees of freedom for error is not much better than having 20, and in such an experiment we could instead consider other treatment or blocking factors and learn more about the problem, rather than using those degrees of freedom purely for \(\sigma^2\).
7.3.2 Contrasts
Contrasts work the same in factorial experiments as they do in other experiments: they are still linear combinations of treatment effects whose coefficients sum to zero. Rather than vectors, their dimension matches the number of treatment factors.
Definition 7.3 (Contrasts in factorial designs) In a factorial experiment, a contrast is a linear combination of parameters \(\tau\) defined by coefficients \(c\). For example, with two treatment factors \(i\) and \(j\), \[
\sum_i \sum_j c_{ij} \tau_{ij} \qquad \text{where} \sum_i \sum_j c_{ij} = 0.
\]
Estimating contrasts is, naturally, easiest in orthogonal designs.
Theorem 7.1 (Contrasts in orthogonal factorial designs) In an orthogonal factorial design, the contrasts (Definition 7.3) can be estimated as \[
\sum_i \sum_j c_{ij} \hat \tau_{ij} = \sum_i \sum_j c_{ij} \bar Y_{ij\cdot},
\] where \(\bar Y_{ij\cdot}\) is the average over replicates. The subscripts can be extended for additional treatment factors.
Proof. TODO
Contrasts can be used to answer useful questions about treatment effects.
Exercise 7.1 (Factorial contrasts) Consider the experiment in Table 7.1. Let \(i\) indicate corn type (1 = basic, 2 = MegaCorn Pro 3.5) and \(j\) indicate fertilizer use (1 = low, 2 = high). Write contrast vectors \(c_{ij}\) for the following three comparisons, and give the contrast estimate for each:
The mean difference between high and low fertilizer use, across both types of corn
The mean difference between basic corn and MegaCorn, across both types of fertilizer
The difference the effect of high fertilizer vs. low for MegaCorn, compared to for basic corn.
And finally, contrasts in factorial designs can be tested. TODO show t test for contrast
7.3.3 Interactions
One common use for inference is answering the question “Do I need an interaction term?” Interactions are not designed into the experiment; they are a feature of the real world, and we have no control over them.
One can construct ANOVA tables with a separate row for the interaction effect, working out the necessary sums of squares for the interaction term and hence constructing an \(F\) test for the interaction. But as you can probably guess, this is equivalent to a partial \(F\) test for the interaction, so you can use the same procedure as you would use in linear regression.
Conventionally, we proceed in two steps:
Test whether an interaction is present (e.g., using an \(F\) test).
If one is present, conduct your analysis using a model with an interaction. If it isn’t, use a model with only main effects.
This procedure is meant to ensure we use the simplest model. Including interactions when they are not necessary makes the model harder to interpret, makes estimates of \(\hat \sigma^2\) less precise (by reducing the error DF), and generally makes life harder. We may as well avoid them unless we need them.
On the other hand, the procedure amounts to post-selection inference, and so inference on the final model is invalid for the same reason that inference after selection is. Our confidence intervals and tests are based on the sampling distribution of the same model parameter estimated with new samples from the population; but we may fit different model parameters depending on the result of the interaction test. We hence underestimate the sampling variation.
My advice: decide in advance whether to use an interaction, whenever that is possible from the background information provided to you.
7.4 Multi-factor blocking
Factorial designs are great. But sometimes we have multiple blocking factors, rather than multiple treatment factors.
7.4.1 Latin squares
We discussed briefly in Section 6.5 that we could handle multiple blocking factors by combining them. If we have a blocking factor with \(k\) levels and another with \(l\) levels, turn that into one factor with all \(kl\) combinations, then do an ordinary blocked experiment.
But that is not necessary—not to achieve a balanced design with orthogonal treatment and blocking factors, anyway.
This naive blocking design would require \(rvkl\) experimental units, where \(r\) is the number of replicates and \(v\) is the number of treatments for the treatment factor of interest. But recall from Exercise 6.11 that all we need for each treatment to appear an equal number of times in each block; that guarantees orthogonality.
Suppose, for instance, we have two blocking factors, each with three levels. We could make a blank grid:
Factor A level 1
Level 2
Level 3
Factor B level 1
B level 2
B level 3
Now we need to allocate treatments to each cell in this \(3 \times 3\) grid to ensure balance. The naive approach is to repeat every treatment in every cell, requiring \(rvkl\) units.
But for factor A to be orthogonal to the treatment, we need only ensure that each treatment occurs the same number of times in each column. For factor B to be orthogonal to the treatment, we need only ensure that each treatment occurs the same number of times in each row. Can we do that?
Well, if \(v = 3\), we can. Let A, B, and C represent the three treatment levels, and then:
Factor A level 1
Level 2
Level 3
Factor B level 1
A
B
C
B level 2
B
C
A
B level 3
C
A
B
Count them: each treatment occurs exactly once in each row and column. If we do \(r\) replicates in each cell, we need only have \(rkl\) units, not \(rvkl\) units—a factor of 3 reduction in this case.
This is called a Latin square design, after the Latin square concept from combinatorics.
Definition 7.4 (Latin square) A Latin square of order \(v\) is a \(t \times t\) grid of \(t\) unique symbols, such that each symbol occurs exactly once in each row and column.
A Latin square design can be applied here because \(k = l = v\): the number of treatment levels matches the number of levels for each blocking factor. Similar Latin squares can be constructed for other numbers of levels, provided they match.
There are many possible Latin squares of a given size; they are equivalent, since they amount to permutations of the rows and columns. To conduct an experiment with a Latin square, we simply randomly assign experimental units to the cells of the square.
Example 7.3 (Generating Latin squares) Latin square designs are easy to generate algorithmically. (Think of them as a very boring Sudoku.) The agricolae package can automatically generate random Latin squares.
For example, suppose we have four treatment levels, labeled A through D. We can ask for an order-4 Latin square:
[,1] [,2] [,3] [,4]
[1,] "D" "B" "A" "C"
[2,] "B" "D" "C" "A"
[3,] "A" "C" "B" "D"
[4,] "C" "A" "D" "B"
We can extend Latin squares beyond the case where the number of levels of each blocking factor is exactly equal to the number of treatment levels. In particular, when the number of blocking factor levels is an integer multiple of the number of treatment levels, we can stack or tile multiple Latin squares. For example, if blocking factor A has 6 levels, factor B has 3 levels, and there are three treatment factors, this is a valid design:
A1
A2
A3
A4
A5
A6
B1
A
C
B
B
A
C
B2
C
B
A
C
B
A
B3
B
A
C
A
C
B
Notice that the left \(3 \times 3\) grid is a Latin square, and the right \(3
\times 3\) is a different Latin square. Both satisfy Definition 7.4.
When you have \(r > 1\) replicates, it may make sense to stack multiple Latin squares. Rather than assigning the replicates to treatments and blocks in the same way—putting them in the same Latin square, \(r\) to a cell—we can make another an equivalent Latin square with a different set of treatment assignments for every group of replicates.
7.4.2 Balanced incomplete block designs
TODO
7.5 Fractional factorials
Look back at Definition 7.1: As we add more treatment factors to a factorial experiment, the number of treatment combinations—and hence the number of experimental units required, as we’re using \(r\) units per combination—grows exponentially. Large factorial experiments can hence become wildly impractical.
But we can sometimes get away with omitting some of the combinations of treatment factors. When done right, we can still estimate the effects we’re interested in. Fractional factorial designs allow us to use only a fraction of the treatment combinations, provided we carefully choose the fraction to allow us to still estimate the effects of interest.
7.5.1 Confounding
Consider a \(2^3\) factorial experiment. There are \(2^3 = 8\) treatment combinations. Call the factors A, B, and C. Consider a full factorial design in which we choose to model the main effects and the AB, BC, AC, and ABC interactions. With intercept and all main effects, we get 8 columns in the design matrix for \(Y = X \beta + \epsilon\): \[
X = \begin{pmatrix}
\text{I} & \text{A} & \text{B} & \text{C} & \text{AB} & \text{BC} & \text{AC} & \text{ABC}\\\hline
1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 1 & 0 & 1 & 0 & 0 \\
1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 1 & 0 & 1 & 0 & 0 & 1 & 0 \\
1 & 1 & 1 & 0 & 1 & 0 & 0 & 0 \\
1 & 1 & 1 & 1 & 1 & 1 & 1 & 1
\end{pmatrix}.
\] (Here the first row is not data but labels, indicating what each design matrix column corresponds to, and I refers to the intercept.)
This linear model is equivalent to the cell means model, \[
Y_{ijkt} = \mu + \tau_{ijk} + \epsilon_{ijkt},
\] as it allows every treatment combination to have a different mean, without assuming additivity of effects.
We can see that if we fit with only \(r = 1\) replicates, we have a perfect fit: \(\beta \in \R^8\), so our model has as many observations as parameters. We will be unable to estimate \(\hat \sigma^2\), since every squared error will be zero. We would need \(r > 1\) to do so.
Alternately: What if we don’t believe we need all the interactions, or believe their effects are small? We can drop the corresponding columns from the design matrix, reducing the number of parameters and allowing us to fit the model and estimate \(\hat \sigma^2\).
7.5.2 Fractional designs
If we don’t believe all the interactions exist, we do not need to estimate as many parameters. We no longer need as many observations to estimate the effects of interest. A design that uses fewer than the full number of factor combinations is called a fractional factorial design.
Definition 7.5 (Fractional factorial notation) In Definition 7.1, we defined an \(l^k\) experiment as an experiment with \(k\) factors each in \(l\) levels. The experiment includes all \(l^k\) combinations of those factors.
In a \(l^{k-m}\) experiment, we only collect data for a fraction of those combinations, where the fraction is \(l^{-m}\).
For example, a \(2^{3-1}\) fractional factorial experiment has 8 treatment combinations but only tests 4 of them.
We can see that it is crucial which fraction we test. Consider the design matrix from above, but only the first four rows: \[
X = \begin{pmatrix}
\text{I} & \text{A} & \text{B} & \text{C} & \text{AB} & \text{BC} & \text{AC} & \text{ABC}\\\hline
1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 1 & 0 & 1 & 0 & 0
\end{pmatrix}
\] In this design, factor A is aliased with the intercept—A is just the intercept times zero—and with interactions AB, AC, and ABC. This is a bad design. We only ever observe A in its baseline level, so we cannot estimate the main effect of A. Evidently we need to choose the specific fraction carefully.
We choose base on the aliasing we are willing to accept. Aliasing is inevitable: some of the columns will be collinear, and aliasing refers to our inability to separately estimate their coefficients. But if, for instance, we believe the interaction effects are likely to be small, we might deliberately alias the main effects with certain interactions, but keep the main effects otherwise estimable. That would be preferable to losing the main effects.
To make the selection easier, we can write out the treatment combinations as \(\pm 1\) instead of 0 and 1. Here’s what we get: \[
\begin{pmatrix}
\text{I} & \text{A} & \text{B} & \text{C} & \text{AB} & \text{BC} & \text{AC} & \text{ABC}\\\hline
+1 & -1 & -1 & -1 & +1 & +1 & +1 & -1 \\
+1 & -1 & -1 & +1 & +1 & -1 & -1 & +1 \\
+1 & -1 & +1 & -1 & -1 & -1 & +1 & +1 \\
+1 & -1 & +1 & +1 & -1 & +1 & -1 & -1 \\
+1 & +1 & -1 & -1 & -1 & +1 & -1 & +1 \\
+1 & +1 & -1 & +1 & -1 & -1 & +1 & -1 \\
+1 & +1 & +1 & -1 & +1 & -1 & -1 & -1 \\
+1 & +1 & +1 & +1 & +1 & +1 & +1 & +1
\end{pmatrix}.
\] Notice we have redefined the interaction columns so they remain the elementwise product of the corresponding main effect columns.
Now we can choose the defining relation, which refers to the effect) we’d like to alias. An obvious choice is \(\text{I} = \text{ABC}\), where \(\text{I}\) represents the intercept column of ones. That is, pick the rows for which the ABC interaction is equal to \(+1\) uniformly. This is “obvious” because we’d rather alias the three-way interaction than the main effects. We select the design \[
\begin{pmatrix}
\text{I} & \text{A} & \text{B} & \text{C} & \text{AB} & \text{BC} & \text{AC} & \text{ABC}\\\hline
+1 & -1 & -1 & +1 & +1 & -1 & -1 & +1 \\
+1 & -1 & +1 & -1 & -1 & -1 & +1 & +1 \\
+1 & +1 & -1 & -1 & -1 & +1 & -1 & +1 \\
+1 & +1 & +1 & +1 & +1 & +1 & +1 & +1
\end{pmatrix}.
\] Because each column only contains \(\pm 1\), and because the interactions are the products of their constituent main effects, we can simply multiply to see aliasing relations. Starting with the defining relation \(\text{I} = \text{ABC}\), we can write: \[\begin{align*}
\text{I} &= \text{ABC} \\
\text{A} &= \text{A}^2 \text{BC} = \text{BC}\\
\text{B} &= \text{B}^2 \text{AC} = \text{AC} \\
\text{C} &= \text{C}^2 \text{AB} = \text{AB},
\end{align*}\] so each main effect is aliased with a particular two-way interaction. We can see these relations match up with the columns in the table, but doing the arithmetic this way means we don’t have to write out the full table.
Returning to the design matrix form, this corresponds to the following design matrix: \[
X = \begin{pmatrix}
\text{I} & \text{A} & \text{B} & \text{C} & \text{AB} & \text{BC} & \text{AC} & \text{ABC}\\\hline
1 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\
1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\
1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\
1 & 1 & 1 & 1 & 1 & 1 & 1 & 1
\end{pmatrix}.
\] In this form, all the interactions are collinear with each other. They will have to drop out of the model for us to fit the regression. So either form agrees that the main effects and interactions cannot be included simultaneously.
7.5.3 Theory of fractional designs
The discussion above tells us the aliasing in each experimental design, but it does not tell us much else about the properties of the designs.
Consider the design we selected, represented in the \(\pm 1\) notation: \[
\begin{pmatrix}
\text{I} & \text{A} & \text{B} & \text{C} & \text{AB} & \text{BC} & \text{AC} & \text{ABC}\\\hline
+1 & -1 & -1 & +1 & +1 & -1 & -1 & +1 \\
+1 & -1 & +1 & -1 & -1 & -1 & +1 & +1 \\
+1 & +1 & -1 & -1 & -1 & +1 & -1 & +1 \\
+1 & +1 & +1 & +1 & +1 & +1 & +1 & +1
\end{pmatrix}.
\] Recall in Exercise 6.11 we made the main effects in a design matrix orthogonal to the intercept. In that exercise, you saw that a column like \((0, 0, 1, 1)\) became \((-1/2, -1/2, 1/2, 1/2)\), which is just \((-1, -1, +1,
+1)/2\). In other words, this \(\pm 1\) notation gives the design matrix columns in their orthogonalized form, so they are each orthogonal to the intercept.
Now consider the A, B, and C main effects. In this form they are also orthogonal to each other. This fractional factorial design, then, still has the benefit of orthogonal main effects and hence uncorrelated variance for their estimates. We also see that each level of A, B, and C occurs an equal number of times, so we will have equal precision in estimating each main effect. We can take these two properties as defining a desirable fractional factorial design.
Fractional factorials can be defined for even smaller fractions (e.g. \(2^{3-2}\) in the above experiment) and for factors with different numbers of levels, and for designs with multiple factors and blocks. The bookkeeping to determine the aliasing structure becomes tedious, but much of it has already been worked out and can be looked up when you are designing an experiment. See Dean, Voss, and Draguljić (2017), chapter 15, for many of the options.
7.6 Exercises
Exercise 7.2 (The efficiency of factorial designs) At the beginning of this chapter, we claimed that factorial experiments are superior to one-factor-at-a-time experiments. Partly this is because factorial experiments allow us to detect interactions, but mainly it is because they require smaller samples to obtain the same information. Let’s demonstrate this.
Consider testing two factors, A and B, each with two levels.
For a \(2^2\) factorial design with \(r_{ij}=1\), derive the variance of the main effect contrasts for treatment A and treatment B, and give the overall sample size \(n\). (Refer back to Exercise 7.1 for main effect contrasts.)
Now consider a one-factor-at-a-time experiment where we fix \(B\) to one level and consider both values of \(A\), each with one replicate. Derive the variance of the main effect contrast for treatment A and give the overall sample size \(n\).
Consider doing a second such experiment for treatment \(B\). Design it so you can reuse one observation from the A experiment. What is the main effect variance, and what is the overall sample size of both experiments put together? Compare this to the factorial experiment.
Repeat steps 2 and 3 for \(r = 2\) replicates. Now compare the main effect variances to the factorial experiment; you should find they are the same. But how does the required sample size compare?
Exercise 7.3 (Insect attraction to light) The CMU Data Repository includes a dataset on insect attraction to light. Read the Motivation section there and download bug-attraction.csv, the data file.
Based on the Motivation text and variable descriptions given, describe the structure of the experiment. The count of insects trapped is the response; what are the treatment factors and how many levels do they have? What are the blocking factors and how many levels do they have? Refer to specific factors by their name in the dataset (such as Light.Type).
Use the factors and blocking variables you identified to count the number of replicates within each treatment and blocking variable. Is this a balanced design? Is it completely balanced, or are there factors not balanced? Are the treatment/blocking factors orthogonal?
Make an interaction plot (Example 7.1) for the two main treatment/blocking factors of interest. Use the response variable Total, the total number of insects captured in each trap. Interpret your plot: Is there a sign of an interaction?
If there is more than one observation per combination, you’ll have to take the mean response to display on the plot.
Note: There is one missing Total observation. You’ll have to remove this before plotting.
Fit two models, one with the interaction and one without. Use just the two treatment/blocking factors you plotted in part 3.
First, is there evidence an interaction is present? State the results of the relevant test.
Then, using the appropriate model, state whether there is evidence of a bulb type main effect. Do the bulbs have different attractiveness to insects?
Exercise 7.4 (The other fraction) In Section 7.5.2, we worked out a \(2^{3-1}\) fractional factorial with defining relation \(\text{I} = \text{ABC}\). What happens if we take the other half, that is, use \(-\text{I} = \text{ABC}\)? Work out the aliasing relations and write out the design matrix. Can we still estimate all the main effects?
Exercise 7.5 (The TOMATO case study)Pollock, Ross-Parker, and Mead (1979) introduced an experimental design case study called TOMATO. We’ll use this case as an opportunity to practice designing an experiment with complex blocking and treatment structure. The experiment centers on how to optimize yield of glasshouse (greenhouse) tomatoes:
Two farmers, Adams and Bloggs, grow glasshouse tomatoes in Guernsey for the English market. After several years, Bloggs clearly gets higher yields than Adams. Unfortunately, Bloggs and Adams have difficulty determining what causes this discrepancy because several factors—heat, light, and variety—differ in their methods of growing tomatoes. Farmer Adams is conservative. He uses standard heating and lighting and a variety of tomato called “Coward,” while Farmer Bloggs uses supplementary heating and lighting and a variety called “Doger.”
There are hence three treatment factors: heat, light, and tomato variety. Each has two levels (standard or supplemental for heat and light, Coward and Doger for variety). The response variable is the yield, in terms of the quantity of tomatoes grown per unit area. The experiment will be conducted in a greenhouse with twelve total plots:
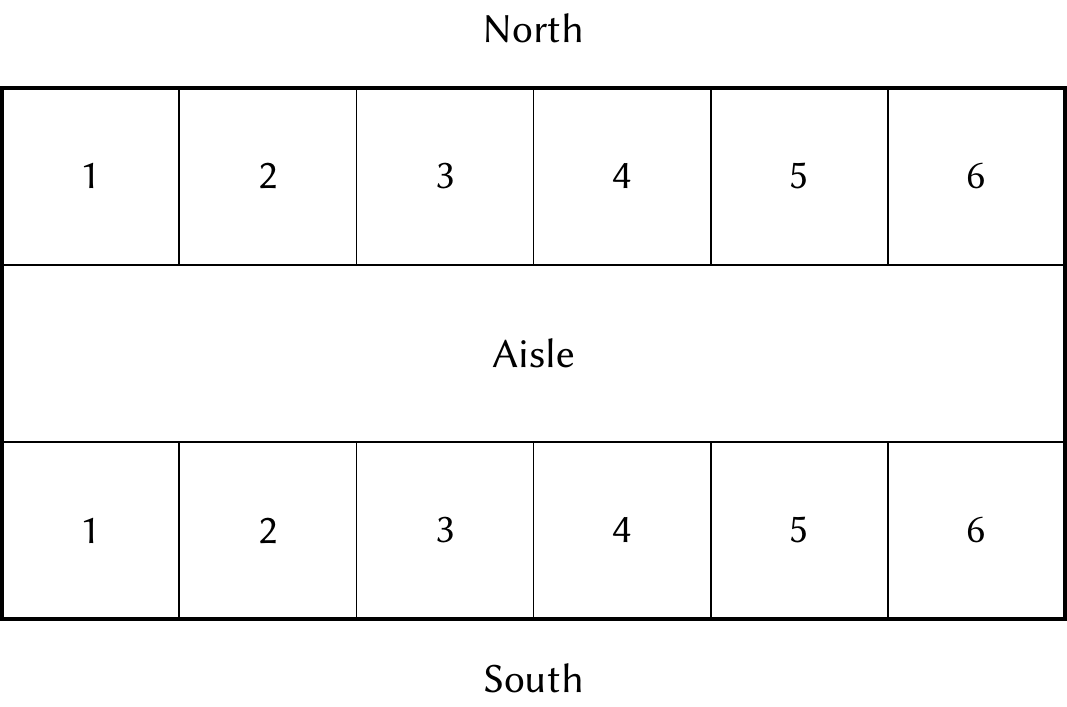
These are lean times and research money is tight; thus you can have only a small greenhouse to perform this experiment. There are six experimental units (plots) facing north and six plots facing south. We know from previous experiments in the greenhouse that there is a substantial difference in yields between the two sides of the greenhouse.
The layout is shown in Figure 7.1. Notice the limitation of the greenhouse layout: there are eight possible treatment combinations, but only six plots on each side of the aisle.
Figure 7.1: Schematic of the TOMATO experiment greenhouse, showing the layout of the plots on each side of the aisle.
Fully describe the experimental setting: How many treatment factors and how many levels (in the notation of Definition 7.1), and how many blocking factors and levels are there?
Consider designing an experiment in two stages. You can assign treatments to all 12 plots in the greenhouse, grow the tomatoes, and obtain results (yield numbers). Then you can run a second stage, assigning further treatment combinations based on the results of the first stage.
Design a first-stage experiment. Give the treatment assignment for each plot in the north and south aisles. Write a paragraph explaining how you arrived at your chosen treatment assignment: what principles did you use to determine how to assign treatments?
Encode your treatment assignment as a data frame in R. Ensure there are only 12 rows and 6 in each aisle. The data frame should have four columns and only specific values in each:
heat: either standard or supplementary
light: either standard or supplementary
variety: either coward or doger
aisle: either north or south
Print it as a table in your solution so your exact treatment design is clear.
Now download tomato-experiment.R and use source() to load it into your R session. This script contains a simulate_tomato() function that generates simulated results of your experiment. Use the function to obtain the results of your experiment. Save them to a CSV file and use this for the rest of the homework (so you don’t get random results each time you re-run your analysis).
Conduct an analysis of the simulated data. Summarize your results.
Now you can conduct the second stage of the experiment. Based on your results, design another treatment assignment, create the data frame, and use simulate_tomato() to get the results of your second experiment. Describe how you chose the design.
Conduct the analysis of your final data and report your overall conclusions.
Pollock, K. H., H. M. Ross-Parker, and R. Mead. 1979. “A Sequence of Games Useful in Teaching Experimental Design to Agriculture Students.”The American Statistician 33 (2): 70–76. https://doi.org/10.1080/00031305.1979.10482663.